How a bid set becomes an RFI log
It runs four checks on the structural sheets and drafts the RFIs hiding in the
contradictions. Three checks are plain code. One is a language model doing the judgment a
reviewer would. Code verifies every quote the model cites before you see it.
Scope: the review runs on structural (S) sheets. Other disciplines are
inventoried so references resolve, and are browsable in the viewer, but are not reviewed.
Drawing setvector PDF
↓
Four checks on the structural sheets
2Dangling detail callouts
code + vision model
4Cross-document review
language model
↓ code verifies every quote the model cites
You accept or dismiss each finding
↓
Exported RFI log
The one design rule. The model only does what code
cannot: read labels drawn as pixels, and judge intent across sheets. Everything checkable is
checked by code, and code decides what may be shown. A model claim that fails verification is
demoted on screen, never silently dropped and never shown as confirmed.
Check 1
Dangling referencescode
Catches: a sheet that points to a sheet the set does not contain.
"See S-3.4" when there is no S-3.4. The classic RFI.
Build a table of contents. Scan each page's
title block for its own sheet id, and map that id to its page. The reader handles the
common conventions (S-1.1, S1.1, S101, S01, and building-prefixed 1.S02) and gates out
look-alikes such as the equipment tag UH-2, so they do not pollute the inventory.
Scan all text on every page for sheet
references.
Flag any reference whose sheet is not in the
inventory.
If the inventory is only partial, for title-block layouts the reader cannot parse, the check
abstains and says so on screen, rather than flag those gaps as missing sheets.
code: engine.py (stage_a)
Check 2
Dangling detail calloutscode+ vision model
Catches: a callout to a detail that was never drawn. "See detail E on
S-5.1" when S-5.1 has no detail E.
The convention it reads. The same little bubble, a detail id over a
sheet id, means two different things depending on which sheet it sits on. On a plan sheet,
"E / S-5.1" is a callout: go see detail E, it is drawn on S-5.1. On
S-5.1 itself, "E / S-5.1" is the title: this is detail E. The only
difference is whether the bottom sheet id equals the sheet you are on.
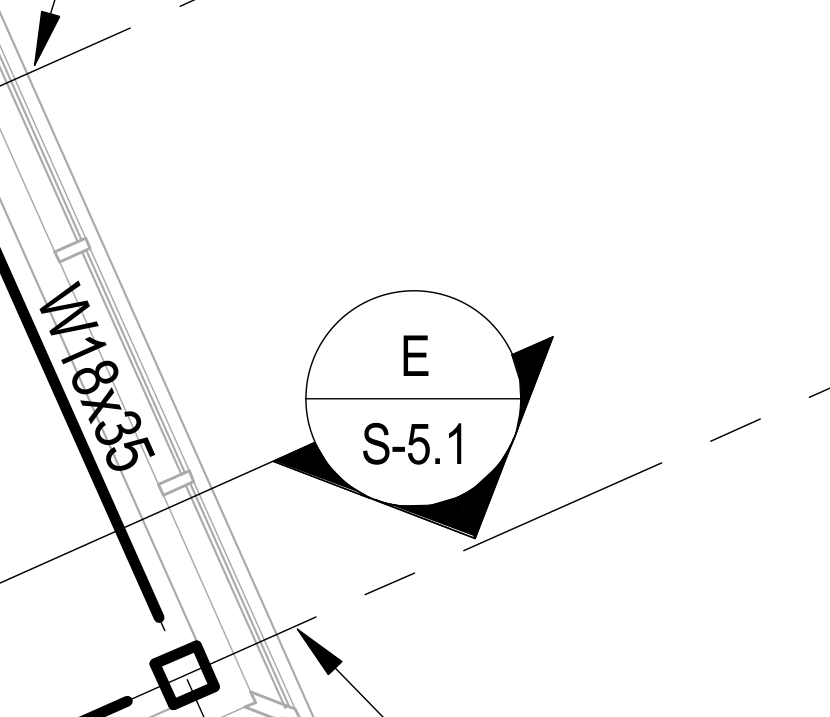
The callout, on Garrett S-1.3: "detail E is drawn on S-5.1". A
promise. If detail E is not on S-5.1, a fabricator finds out during shop drawings and
writes an RFI.
The title that keeps it, on S-5.1: "E / S-5.1, SECTION". The same
E, now labeling a real drawn detail. These titles are drawn graphics with no text
layer, so code cannot read them; the vision model reads them off the pixels.
Code splits the bubbles. It reads the id and
sheet tokens from the text layer, pairs the ones sitting next to each other, and labels
each pair a callout or a title with the one rule above.
The vision model reads the titles code cannot.
For every sheet a callout points at (capped at six), it renders the sheet to tiles and
lists the detail titles drawn on it. It is told to report titles only and ignore
callouts.
Code matches. Each callout's detail id is
looked up in the titles on its target sheet. No match means the callout is flagged,
marked perception-based so a human confirms it on the sheet.
code + model: engine.py (stage_a extracts, stage_b reads titles and resolves)
Check 3
Marks vs schedulescode
Catches: a component placed but never defined, or defined but never
placed. A C3 column drawn on the plan with no C3 in any schedule.
A mark labels a component type (C3 = column type 3). The plan places
marks; a schedule is the table that defines them. The two should agree
in both directions.
Find every mark on the structural sheets (a family letter, C/P/F/WF/B/G/J,
followed by a number).
A mark sitting inside the box around a "...SCHEDULE"
header counts as defined. A mark anywhere else counts as placed.
Per family, flag the two set differences:
placed but never defined, and
defined but never placed.
Finding the schedules by their "SCHEDULE" headers, rather than a fixed position, is what
lets the check work across sets with different layouts.
code: engine.py (stage_a)
Check 4
Cross-document reviewlanguage model+ code verifies
Catches: contradictions and gaps that need judgment, not a pattern. A
wind importance factor written 1.0 in one note block and 1.15 in another. Information a bidder
needs that no sheet provides.
Code picks the pairs. It sorts the structural
sheets by type and makes up to five comparisons an engineer would do: notes vs each plan,
plan vs framing, plan vs sections. No model input here.
The model reviews each pair as a senior
engineer doing pre-issue QA. For every problem it returns a finding labeled
conflicting, missing, or ambiguous, the verbatim quotes that create
it, a draft RFI question, and a proposed resolution. Zero findings is an allowed answer;
it is told not to manufacture problems.
Code verifies every quote. Each quote must
appear word for word in the cited sheet's text. All found means verified; some means
partial; none means unverified, which is demoted and never shown as confirmed. Verified
quotes are located and pinned on the drawing.
Absence claims get an adversarial recheck. A
"missing" or "ambiguous" claim asserts a negative, which a quote cannot prove. So a second
model pass tries to find the supposedly missing statement in the same text. If code
verifies what it finds, the finding moves to a "refuted on recheck" bucket, shown for
audit. (Earned: a finding called the concrete strength for a raised slab ambiguous while
note 6 on the same sheet specified 4,000 psi for elevated slabs.)
model + code: engine.py (pick_pairs, stage_cd; prompts and schema are
TITLE_PROMPT, REVIEW_PROMPT, REFUTE_PROMPT, REVIEW_SCHEMA)
What verification proves, and what it does not. A
verified quote proves the cited words exist on the cited sheet. It does not
prove the model's reading is right. That is why every card is a draft question with receipts, why
you accept or dismiss each one, and why the export is an RFI log, not a defect list.
Appendix
Cost, caps, limits
| model | loading... |
|---|
| metering | token usage from each API response is the accounting source of
truth; the budget is checked before every call; hard cap per run;
the run aborts rather than overspends. Typical full run: $0.45 to $0.90. |
|---|
| caching | responses are cached by a hash of model, prompt, and images.
Identical inputs replay free and instantly; any new input runs live. Caching is an
accelerator, not the mechanism. |
|---|
| limits | a vector text layer is required (scans would need OCR, with its own
error budget). Title-block layouts beyond the right and bottom strip patterns stop the run
with "layout unsupported" rather than guess. Pair selection is a heuristic, so an
unpaired conflict can be missed. Findings drift slightly between fresh runs. Review is
structural-discipline only. False-positive classes found while validating on four public
sets are fixed in code, each with a comment naming the set that exposed it. |
|---|
the whole pipeline is one file: engine.py